Mesurer la performance avec Locust
Toute application doit pouvoir répondre à un certain nombre de requêtes sous un temps minimum jugé comme acceptable. Ceci peut varier énormément. Google fait face à des millions d’utilisateurs et se fixe des objectifs de performance très ambitieux. D’un autre côté, un système de gestion d’inventaires d’une petite épicerie difficilement aura plus d’une poignée d’utilisateurs et n’aura pas les mêmes contraintes de temps de réponse.
Les tests de charge servent à assurer que notre application réponde à nos objectifs liés au nombre d’utilisateurs simultanées et temps de réponse. C’est là que Locust rentre en action : un outil pour simuler des utilisateurs virtuels et permettre leur analyse. Par rapport aux alternatives Locust a un grand plus : on écrit nos tests en Python pur et dur.
Préparons le terrain
Avant de jouer avec Locust, il faut bien qu’on ait quelque chose à tester. Pour le fun, nous allons faire un hello-world avec Flask.
Je vais d’abord démarrer un environnement virtuel avec Python 3 dans un dossier vide, suivi de l’installation de Flask avec pip :
» virtualenv -p python3 venv
» . venv/bin/activate
» pip install flaskCréons maintenant un fichier hello.py avec le code disponible dans le site Flask.
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'Et voilà, nous avons un endpoint sur http://127.0.0.1:5000/.
» export FLASK_APP=hello.py; flask run
* Serving Flask app "hello.py"
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)Locust entre en jeu
Locust permet de simuler de milliers d’utilisateurs simultanés sur notre app. Derrière le rideau, il crée un processus léger via gevent (plus précisément un greenlet) par utilisateur simulé. Ce choix technique permet de simuler un grand nombre d’usagers sur une seule machine.
Commençons par créer un fichier locustfile.py. Ce fichier servira pour décrire les tests de charge.
from locust import HttpLocust, TaskSet, task, between
class UserBehaviour(TaskSet):
@task
def index(self):
self.client.get("/")
class WebsiteUser(HttpLocust):
task_set = UserBehaviour
wait_time = between(5, 9)La class UserBehaviour nous permet de définir l’activité que les usagers vont mener. Dans notre cas il y a un seul et unique endpoint à la racine qu’on represente ici avec la fonction index décoré avec @task pour indiquer à Locust qu’il s’agit d’une tâche que les utilisateurs vont effectuer.
La class WebsiteUser represente l’utilisateur lui même. On spécifie la task_set qu’il réalisera ainsi que le temps qu’il attend entre chaque tâche - entre cinq et neuf secondes dans notre cas.
Si vous avez nommé ce fichier locustfile.py il suffit de taper locust dans la console pour tout démarrer. Si vous l’avez nommé différemment il faudra ajouter -f <<path-to-file>>
» locust
[<date>] /INFO/locust.main: Starting web monitor at http://*:8089
[<date>] /INFO/locust.main: Starting Locust 0.14.4Locust a mis en place l’interface web sur http://localhost:8089. Cette interface nous permet de spécifier le nombre d’usagers à simuler, le taux de création de ces utilisateurs et l’URL de l’application à tester. Démarrons nos tests avec 100 utilisateurs avec un taux de croissance de dix par seconde. Vu que notre hello-world Flask tourne toujours sur le port :5000 on peut le remplir comme cela :
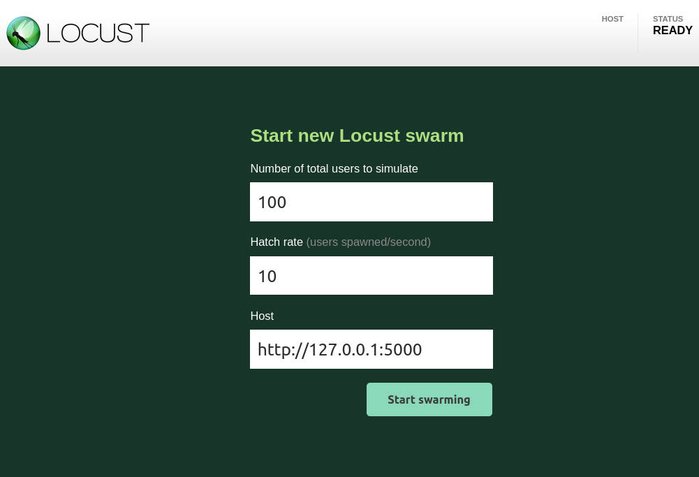
Après avoir appuyé sur le bouton start swarming le test se met en œuvre. Dans l’entête de la page on trouve le nombre d’utilisateurs simultanées, les requêtes par seconde (RPS) et le pourcentage d’échec. Plus bas, dans la table on peut aussi connaître le temps de réponse de notre application.
Notez aussi les onglets :
- Charts contient des visualisations concernant les temps de réponse, les requêtes par seconde et le nombre d’usagers,
- Failures et Exceptions donne davantage d’information sur les problèmes rencontrés lors du test, et
- Download Data permet de télécharger les données bruts en CSV.
Plus d’endpoints
Dans la vie réelle on voudra tester des applications qui ont plus d’un endpoint. Par exemple, on peut avoir de comptes utilisateur (et donc un /login et /logout). Puis on pourrait aussi mettre à disposition un endpoint pour paramétrer le compte (/account) ainsi qu’un autre pour accéder au panier d’achat (/cart).
Ajoutons ces nouvelles routes à notre app Flask sur hello.py :
from flask import Flask
app = Flask(__name__)
@app.route('/')
def home():
return 'Home'
@app.route('/login')
def home():
return 'Login'
@app.route('/logout')
def home():
return 'Logout'
@app.route('/account')
def home():
return 'Account'
@app.route('/cart')
def home():
return 'Cart'Authentification
Cette fois-ci nos utilisateurs doivent s’identifier avant d’accéder aux autres pages. De plus, ils fermeront leur session après avoir fini. Les fonctions on_start et on_stop sont appelées avant l’exécution de la première tâche et après la fin du TaskSet respectivement. C’est donc idéal pour placer l’authentification :
...
class UserBehaviour(TaskSet):
def on_start(self):
self.client.get('/login')
def on_stop(self):
self.client.get('/logout')
...Comportement des usagers
Vu le nombre des pages dans notre app, ce serait utile de paramétrer UserBehaviour pour que les pages ne soient pas toutes visitées pareil. Nous pouvons nous attendre à que la page d’accueil (/) soit souvent visité. D’un autre côté, du fait que les utilisateurs ne paramètrent pas leur compte tous les jours, /account ne sera pas un passage obligé pour tous. Finalement, le panier d’achat (/cart) se situe un peu au milieu en terme d’affluence.
Pour ce faire on s’appuiera sur le décorateur @task, plus précisément sur son paramètre facultatif entier qui répresente le poids, çad la probabilité qu’un utilisateur choisisse la tâche en question pour son action suivante. Une tâche @task(10) a dix fois plus de probabilité d’être choisie qu’une tâche @task(1). Nous pouvons donc récrire notre locustfile.py de la façon suivante :
from locust import HttpLocust, TaskSet, task, between
class UserBehaviour(TaskSet):
def on_start(self):
self.client.get('/login')
def on_stop(self):
self.client.get('/logout')
@task(10)
def index(self):
self.client.get("/")
@task(5)
def cart(self):
self.client.get("/cart")
@task(1)
def account(self):
self.client.get("/account")
class WebsiteUser(HttpLocust):
task_set = UserBehaviour
wait_time = between(5, 9)Si on applique les mêmes paramètres que lors du dernier test, on obtient ces résultats :
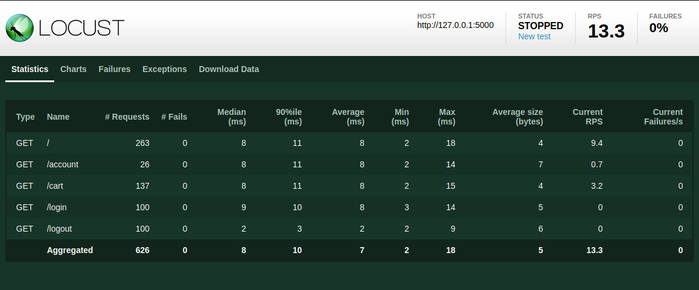
On constate que chacun des 100 utilisateurs s’est identifié et a fini par fermer sa session. Le poids qu’on a assigné aux tâches a bien été respecté : la page d’accueil a été visité autour de dix fois plus que celle de paramétrage du compte et deux fois plus que le panier d’achat.
Locust en mode distribuée
Si nos besoins de simulation sont trop importants pour être faits sur une seule machine, Locust permet d’exécuter les tests de façon distribuée. Il suffit de créer une instance Locust master (avec l’option -master) à laquelle on ajoutera des noeuds créés avec l’option slave et ---master-host pour indiquer où se trouve l’instance maître.
Sur une machine on ferait :
locust -f mon_locustfile.py --masterEt on ajouterait des noeuds avec :
locust -f mon_locustfile.py --slave --master-host=192.168.0.14En conclusion
Locust met à disposition des outils simples et puissants pour mesurer le comportement d’un système en fonction de la charge d’utilisateurs simultanés. La courbe d’apprentissage est particulièrement rapide, la documentation est claire et la flexibilité apportée par le choix de Python pour décrire les tests offre des vastes possibilités pour des cas spéciaux. L’interface graphique est plutôt basique, mais les données bruts sont disponibles pour ceux qui ont besoin de les traiter davantage.
J’ai mis en place Locust pour mon projet actuel et je ne peux que le recommander.
Comparaison avec JMeter
JMeter est basé sur Java et contient une interface graphique pour décrire nos tests, contrairement à Locust où on se sert du code Python. Je ne trouve pas leur UI très ergonomique : les cas d’usage de base sont plutôt difficiles à effectuer et souvent nécessitent des plugins externes pour fonctionner.
Comparaison avec Tsung
Tsung est basé sur Erlang et la machine virtuelle BEAM, un très bon choix pour une application basé sur des processus légers concurrents. Par contre, Tsung a besoin d’un fichier xml cauchemardesque pour décrire les tests. De plus, le projet a l’air plutôt dormant depuis un an.
